Latency matters. Amazon has reported that for every 100mS of latency, it costs them 1% in sales. Google has reported that 500mS additional latency dropped traffic by 20%. A broker could lose $4 million in revenue per millisecond if their electronic trading platform is 5ms behind the competition.1
So would that imply that a zero latency would mean infinite sales? Probably not, but the point is that latency exists and is part of our life.
I've personally said for over 20 years now that it is a mistake to assume latency is just the inverse of bandwidth. In a paper presented at UC Berkley, David Patterson studied bandwidth and latency improvements over a 20 year window to some disappointing results:
- CPUs gained 2250x MIPS (millions of instructions per second) improvement and latency improved only by 22
- Networks improved bandwidth by 1000x and latency improved by only 15x
- Rotating storage improved bandwidth by 140x, whereas latency only improved by 8x
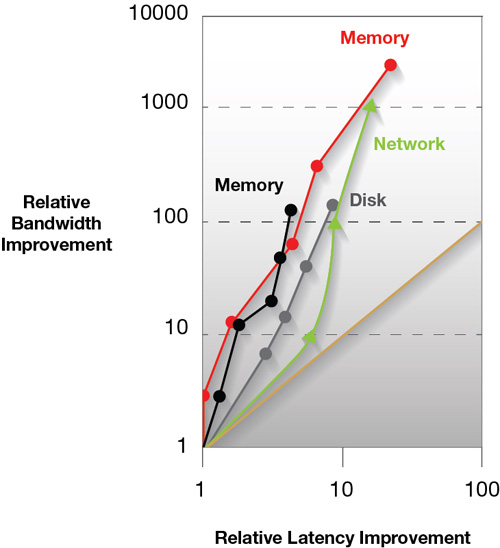
From this, David Paterson came up with a couple of rules of thumb:
- As bandwidth increases by 2x, latency only improves by ~1.2x
- Bandwidth improves by more than the square of the improvement in latency
Hyperscalers have immense challenges as they design their data centers. Network latency was a key point for them and have taken tremendous lift in designing custom network stakes and back planes. One hyperscaler reported that they currently have less than 250uS latency between any node in the same data center and no more than 1-2 ms latency between Availability Zones in the same region2. Even more impressive is they reduced the 99.9% tail latencies by an order of magnitude.
With all the network latency gains archived, one of their next significant targets is storage latency. At the 2017 Flash Memory Summit, Chris Petersen from Facebook reported that a typical SSD operating at a read workload can have an over 35x latency tail variation pushing from the expected ~100uS range to an over 4-5mS range! Read tail latencies are exceeding network latencies by almost 3X! Obviously a solution is needed.
So what is the source of these tail latencies? At this year’s Flash Memory Summit, I gave a bit of color to this. Although the host is capable of requesting simultaneous reads and writes, typically the SSD processes these requests as fast as possible. But fundamentally a single flash LUN is capable of only a single read, program or erase operation at the same time. The impact to this is shown from simulation data in figure 1 below:

Source: Internal Toshiba Testing, March 2017
From this we can see that 99 reads in a hundred are able to run at full speed, but about one read in 1000 is impacted waiting for a program operation to complete and about one read in 10,000 is stuck waiting for an erase to complete. Whether we're waiting 5mS or 10mS for the erase to complete, it’s unacceptable.
A solution must be found. To be continued…
1Highscalability.com, 2009
2Cloudacademy.com, 2014
Disclaimer
The views and opinions expressed in this blog are those of the author(s) and do not necessarily reflect those of KIOXIA America, Inc.